Nuevo profesional del Doctorado en Ciencias de la Computación
Sergio Burdisso defendió su tesis del “Doctorado en Ciencias de la Computación”, carrera de posgrado de la Facultad de Ciencias Físico Matemáticas y Naturales (FCFMyN), que se dicta en el Departamento de Informática.

Dicha tesis se tituló “Determinación del Perfil del Autor en Contextos de Clasificación Anticipada de Textos para Múltiples Dominios”, dirigida por el Dr. Marcelo Errecalde (UNSL) y co-dirigida por el Dr. Manuel Montes y Gómez (Instituto Nacional de Astrofísica, Óptica y Electrónica, México)
El jurado a cargo de la evaluación estuvo integrado por:
Presidenta: Dra. Marcela Printista (Decana de la FCFMyN)
Dr. David Enrique Losada Carril (Universidad de Santiago de Compostela, España)
Dr. Alfonso Ureña López (Universidad de Jaén, España)
Dr. Guillermo Leguizamón (UNSL)
El flamante Doctor en Computación contó lo que significa culminar su carrera de posgrado en la FCFMyN: “Es un momento de felicidad por haber logrado cerrar este ciclo de varios años en mi vida. Asimismo, estoy con esa mezcla de incertidumbre y emoción propia de todos los cierres de ciclos en la vida, en los que al terminar una etapa, una nueva comienza”.
– ¿Por qué elegiste este tema de investigación?
-Siempre sentí mucha curiosidad e interés por la Inteligencia Artificial. Por lo que, una vez concluida la Licenciatura, me contacté con el Dr. Marcelo Errecalde, docente de la Facultad, para consultarle por posibles temas de investigación para abordar en el doctorado, y entre ellos, elegí este tema porque me pareció el más interesante y a su vez el más desafiante.
– ¿Cómo es el proceso para la determinación del perfil de un autor en el contexto estudiado?
-El contexto estudiado fue la detección anticipada de riesgo en redes sociales, en particular la experimentación y puesta a prueba del modelo desarrollado se llevó a cabo en la determinación del perfil psicológico de los usuarios. Siendo más precisos, las tareas puntuales abordadas fueron la detección anticipada de depresión, anorexia y conductas autodestructivas en usuarios de Reddit, utilizando los datos de un desafío anual denominado “eRisk” (Early Risk Detection on the Internet) en el que diversos equipos de investigación de todo el mundo participan año a año. En el año 2019, participamos utilizando el modelo desarrollado y obtuvimos los mejores resultados entre todos los equipos de investigación participantes.
En este contexto, el proceso de determinación del perfil (psicológico) del autor en relación a trastornos mentales es llevado a cabo automáticamente por el modelo desarrollado en sí mismo. El modelo desarrollado, al cual llamamos SS3, utiliza un conjunto de ecuaciones que le permiten aprender a valorar las palabras automáticamente en relación al trastorno en cuestión, luego, a medida que procesa el contenido generado por los usuarios va acumulando evidencia en base a las palabras procesadas, hasta que eventualmente, el modelo acumula la suficiente evidencia como para poder decidir qué usuarios están en riesgo por padecer dicho trastorno.
-¿Qué tan fácil es para una persona comprender los modelos interpretables y los modelos explicables?
-Se dice que estos modelos son interpretables si son fáciles de comprender para un humano, es decir, si es fácil de comprender las razones por las que el modelo toma una decisión en base a la entrada procesada. Por otro lado, cuando el modelo es lo suficientemente complejo, no es posible comprender las decisiones que toma, en este caso, se deben utilizar técnicas y mecanismos especiales que intenten explicar, mediante aproximaciones, el funcionamiento de estos modelos. En este último caso se dice que los modelos no son interpretables, sino explicables. En tareas de riesgo que involucran, o se espera que involucren, la vida de personas reales, como las abordadas en el doctorado, se espera que los modelos sean interpretables por un humano, no explicables, ya que de este modo los modelos serán transparentes y , por lo tanto, confiables.
-¿Cómo se logra saber si un modelo es transparente y confiable?
-Un modelo será transparente y confiable si es fácil para los humanos poder comprender sus decisiones. De esta forma, la decisión final puede ser manualmente analizada y validada por humanos expertos en el dominio abordado (por ejemplo, un experto en enfermedades mentales). En caso contrario, cuando el modelo es complejo y “oscuro”, funciona como una caja negra, la cual recibe la entrada y produce una salida, pero sin “dejar ver” cómo funciona su interior. Por lo tanto, los humanos no pueden validar dichas decisiones (un ejemplo de modelos “oscuros” serían las redes neuronales profundas, que constan de miles de millones de parámetros, y que son ampliamente utilizadas por nosotros indirectamente día a día, cada vez que YouTube nos recomienda un video, Netflix una película, Facebook nos muestra publicidad, entre otros).
-¿Qué se entiende por valoración de palabras?
-Como se explicó anteriormente, el modelo desarrollado parte de aprender a valorar las palabras en relación a la tarea abordada. El modelo se formuló de forma general, y puede aprender dicha valoración sin depender de ningún tipo de tarea en particular, siempre que se dispongan de datos para entrenarlo (por ejemplo, contenido de usuarios, noticias, libros, etc. Dependerá de la tarea abordada lo que “datos” signifique). Personalmente, creo que el mayor aporte de mi doctorado fue el haber podido crear este conjunto de ecuaciones que le permiten al modelo aprender a valorar las palabras en base a los datos procesados. La diferencia que tienen estas ecuaciones con otras ya existentes, es que fueron creadas con el objetivo de aprender una valoración que es intuitiva de comprender para los humanos, intentando imitar una valoración similar a la que haría un humano. En la última etapa del doctorado desarrollé una herramienta que, coloreando cada palabra con una intensidad proporcional al valor aprendido, le permite a los investigadores o expertos humanos en el dominio abordado, comprender visualmente las razones en base a las cuales el modelo tomó la decisión. También dejé disponible en línea (http://tworld.io/ss3/) dos demos que permiten probar esto en línea.
-¿Cómo se lograría un clasificador ideal de textos de múltiples dominios?
-Dependerá de los dominios abordados. En nuestro caso particular, los dominios abordados fueron todos de detección anticipada de riesgo en línea. En la primera parte del doctorado delineamos qué características debería tener un clasificador (modelo) ideal para abordar dominios de detección anticipada de riesgos en redes sociales. En este sentido, dado que en estos dominios los modelos deben:
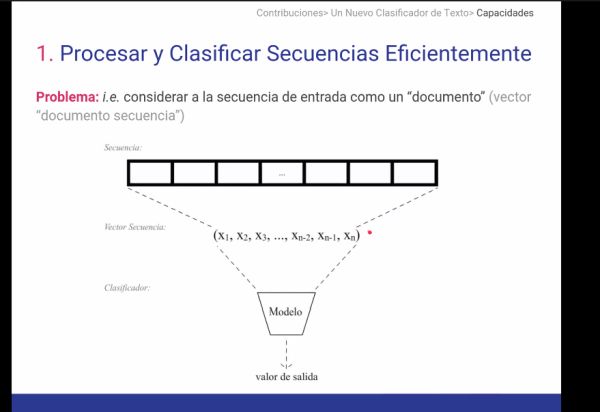
1. Procesar un flujo continuo (e infinito) de texto correspondiente a la secuencia de publicaciones/texto de los usuarios.
2. Poder decidir si la información procesada es suficiente para clasificarlos.
3. Ser transparentes y confiables.
Un modelo ideal debe poder abordar estos tres aspectos de una forma eficiente e integral, por lo que determinamos que un modelo ideal debe poseer, al menos, las siguientes características:
1. Poder trabajar/funcionar incrementalmente.
2. Capturar, contener y sintetizar, desde la secuencia de entrada, la suficiente información como para poder decidir cuándo clasificar con efectividad.
3. Ser un modelo interpretable, con capacidad de explicarle visual y naturalmente la clasificación al humano.
El modelo desarrollado durante el doctorado se creó con el objetivo de poseer estas tres características de una forma integral.
– ¿En qué ámbito trabajás actualmente?
-Más allá de la tarea docente que llevo a cabo hace unos años como auxiliar de primera en el Departamento de Informática, no estoy realizando ningún otro trabajo porque la beca doctoral de CONICET no permite tener otro trabajo. De todas formas, ahora que terminé el doctorado y ya no tengo la beca, tengo que decidir cuál será “el siguiente paso”, decidir si trabajaré en el sector privado o si continuaré por el camino de la investigación, por ejemplo, realizando un postdoc en el exterior por unos años.
– ¿Por qué es recomendable cursar el Doctorado en Ciencias de la Computación?
-Depende de la personalidad de cada persona lo que puede adaptarse mejor a cada uno. En mi caso, además de siempre tener ganas de aprender cosas nuevas, soy una persona muy curiosa a la cual no le gusta utilizar algo sin querer saber cómo funciona o por qué funciona, constantemente estoy indagando y profundizando al respecto. Eso me dio a entender que tengo un perfil que encaja bien con el perfil científico. En el caso de la computación, siempre estoy indagando por cómo todo funciona, intentando comprender cada vez más y más todos los niveles de abstracción involucrados en lo que conocemos como “la computadora”, desde los transistores hasta lo más abstracto, como la Inteligencia Artificial. El Doctorado en Ciencias de la Computación podría ser recomendable para las personas que sean curiosas, que les guste indagar, aprender y profundizar en el tema de investigación abordado. También para personas que les gusten los grandes desafíos, ya que probablemente tendrán que trabajar en el límite de lo que puede, o no, ser resuelto computacionalmente, buscando aportar ese granito de arena que permita expandir dicho límite un poco más, para finalmente, como científico, brindarle a la humanidad ese conocimiento generado por medio de, por ejemplo, publicaciones de artículos científicos y/o materializado en forma de software.